LLMの小型化が生成AIの課題を解決
2022年11月のChatGPTリリースをきっかけに世界中が生成AIブームに沸いています。 ChatGPTに代表される生成AIに対する世の中の関心は高まるばかりで、一過性の”ブーム”に終わらないことをみなさんが言及し始めました。 ChatGPTをはじめとする、生成AIのコア技術である「LLM(Large Language Models/大規模言語モデル)」について、および、LLMの課題について言及し、その上で、弊社の技術「キャッシュAI」がその課題解決に迫ることをご説明します。
LLM(大規模言語モデル)とは?
膨大なデータによる学習とディープラーニング(深層学習)技術を用いて構築された、自然言語処理(NLP:Natural Language Processing)のモデルのひとつです。 「大規模」とは、従来の自然言語モデルと比べ、3つの要素「計算量」「データ量」「パラメータ数」を大幅に増やして構築されていることに由来します。「計算量」とはコンピュータが処理する仕事量のことで、「データ量」とはコンピュータに入力した文章データの情報量です。また「パラメータ数」とは、ディープラーニング技術に特有のパラメータ(確率計算を行うための係数の集合体)の豊富さを指します。
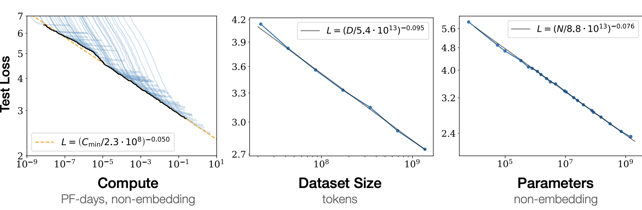
上記は、2020年にOpenAIが発表した論文で示された図で、「計算量」「データ量」「モデルパラメータ数」の3つの各要素の量が多くなると機械学習loss(損失)が減少することを表しています。lossは予測値と実測値の乖離を表し、lossの値が小さいほどモデルの精度が高まることを示します。つまり、この図から、「計算量」「データ量」「モデルパラメータ数」が大きくなるとモデル精度が向上することが示されています。ChatGPTも「大規模言語モデル」の一種であり、格段に優れた受け答えにより、自然言語での応答の質を大幅に高めています。
小型言語モデルの必要性の高まり
小型言語モデルとは、10億個以下のパラメーター数の言語モデルをいいます。それでもかなり大きいですが、1000億を超えるといわれるOpenAIのChatGPTやGoogleのBardなどの大型言語モデル(LLM)のパラメーター数に比べるとはるかに小さいです。
企業は生成AIの活用に注目していますが、ChatGPTのような大型言語モデルは企業での利用には課題があります。 米国企業の調査では、セキュリティやプライバシーその他の懸念を理由に、組織の75%が生成AIアプリケーションの禁止を検討または禁止を実施していると報告されています。(出所:Why Are So Many Organizations Banning ChatGPT?) さらに、LLMの学習コストが高いことも、導入の大きな障壁になっていると考えられています。
そこで、生成AIからの情報価値を得るために、モデル維持にかかる時間的・人的コストが少なく、企業の既存のセキュリティ境界内で運用できる、小型言語モデルが、米国では今後のトレンドとなるといわれています。 小型言語モデルは、今までの大型言語モデルのように、すべてを実行するのではなく、狭いタスクのセットに対して最適化されているため、高速かつ正確になります。
パブリックLLMの課題に応える小型言語モデル
ChatGPTのようなパブリックLLM(企業の枠を超えて利用するLLM)は「基礎」モデルとして知られており、ケーキの焼き方から株式ポートフォリオのバランスの取り方まで、あらゆるトピックに関する質問に答えるために、インターネットから膨大な量の情報を収集して作成されています。 一般知識の質問には良い回答をしますが、多くのことをやろうとするためエラーが発生しやすく、構築と維持に膨大な量の計算処理能力が必要です。
パブリックLLMは、企業がセキュリティ管理している機密性の高い顧客データ、財務データ、その他の機密データにアクセスできないため、組織固有の質問に答えることが苦手です。組織データをパブリックLLMに与えることは、企業にとってセキュリティとプライバシーのリスクが高いことが導入障壁となります。
生成AIはビジネスにとって非常に強力なツールとなり得るため、このことはビジネスの機会損失となります。例えば、適切なデータがあれば、アカウントエグゼクティブは「解約しやすい顧客を示し、顧客とのエンゲージメントを維持するための提案をしてください。」という質問ができます。また、マーケティング担当者は、「過去のケースでの効果に基づき、第4四半期の新製品発売に向けたキャンペーンのアイデアを教えてください」と尋ねることができます。
この種の質問を可能にするための鍵となるのは、企業にとって安全なクラウド環境内で運用および学習させられるプライベートLLMです。企業がプライベートLLMを構築するためには、構築コストや運用コストを下げるためにLLMを小型化する必要があります。小型言語モデルです。 小型言語モデルは、企業の最も機密性の高いデータで学習することでカスタマイズできます。データはパブリックLLMに入力する必要がなく、モデルが小さいため、必要なコストが大幅に削減されます。
企業で活躍する小型言語モデル
ChatGPTのようなLLM は、1000億を超えるパラメータに基づいて学習されており、ChatGPTの構築と運用には莫大なコストがかかります。ChatGPTの学習コストは推定400万ドルです。
小型言語モデルは、10億個以下のパラメーターに基づき学習します。ChatGPTやBardなどの基本的なLLMよりもはるかに小さいです。 これらは語彙や人間の音声を理解するように事前に学習されているため、企業や業界固有のデータを使用してカスタマイズするための追加コストが大幅に削減できます。
言語モデルが小さいとコスト削減できるだけでなく、より正確になります。 悪い点も含めた公開データをすべて学習するのではなく、正確に質問に回答できるように、ビジネスで重要なユースケースに対して慎重に精査されたデータを学習、最適化するからです。
しかし、企業内部のデータに限定されるわけではありません。小型言語モデルには、経済、商品価格、天候、または必要なデータセットに関する外部データを組み込んで、独自のデータセットと組み合わせることができます。
Geek GuildのキャッシュAI
Geek GuildのキャッシュAIはこのような時代の到来を想定して、地道に研究開発してきたAIモデルの小型化技術です。企業がAIモデルを構築し運用できるようにと、AIモデルの小型化を進めてきました。 ChatGPTの登場により、LLMの小型化の必要性が認知され、キャッシュAIが世の中に貢献する時代となりました。
LLMの未来
現在の検索エンジンの変遷のように、将来的には、世界で広く使用される基礎的なLLMは、Meta、Google、Baiduなどのテクノロジー大手が運営する数十だけが残るといわれています。 巨大なLLMの維持には膨大なリソースが必要だからです。
しかし、何千もの小型言語モデルが企業または部門レベルで運用され、従業員に貴重な洞察を提供する未来をつくるために、小型言語モデルは実用化の可能性があり、ビジネス向けの生成AIの真の力を引き出す鍵となります。(出所:Why downsizing large language models is the future of generative AI)

2024-03-19:generative AI


