AIの小型化技術
Geek Guild のAIの小型化技術について
目的
創業以来、AIの小型化を進めています。 AIの実運用の際に課題となるサーバー費用に着目し、 サーバー費用を削減するためにAIの小型化の研究開発をいち早く進めています。
ディープラーニングの学習済みモデルを小型化することで軽量・高速化を実現。 それにより、学習済みモデルの運用に必要なサーバー処理の負荷を軽減し、サーバーコストを削減します。 AI製品サービスの原価の大半を占めるサーバー費用を削減し、製品サービスを手頃な価格で提供します。
技術について
小型化の手法は様々ですが、当社では主に2つの方法「量子化」と「キャッシュAI」の研究開発を進めています。
小型化の手法の説明の前に、ディープラーニングの初学者向けに簡単に「重み付け」についてご説明します。
ディープラーニングでは、「学習(training)」フェーズと「推論(予測)」フェーズがあります。
大量のデータをニューラルネットワークに読み込ませ、
シナプスの「重みづけ」を最適に調整したネットワークを作り上げることを「学習」といいます。
例えば、熊の画像認識の場合、熊のデータを「学習」させ、画像を与えた時に「学習」した熊の画像に近いと判断すると
「熊である確度が90%である」などという「推論」をします。
与えた画像が熊の画像でなかった場合は、認識精度が悪いということになり
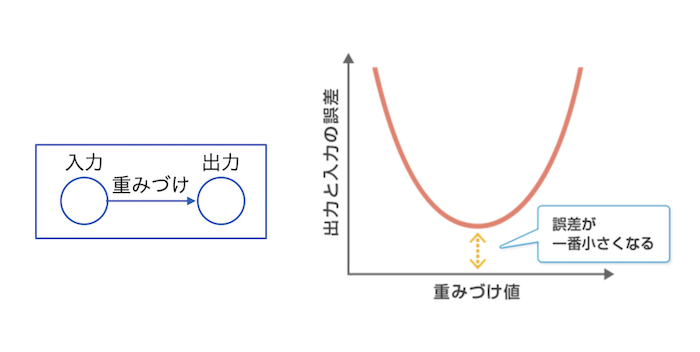
「誤差逆伝搬(バックプロパゲーション)」で調整をします。「誤差」というのは、入力の「熊」と出力の差です。
この誤差を最小にするシナプスの重みづけを出力から入力の逆方向に向かって計算してゆく手法です。
ニューラルネットワーク内の重みづけを調整し続け、「熊」を学習していくのがディープラーニングで、
学習されたモデルが学習済みモデルです。
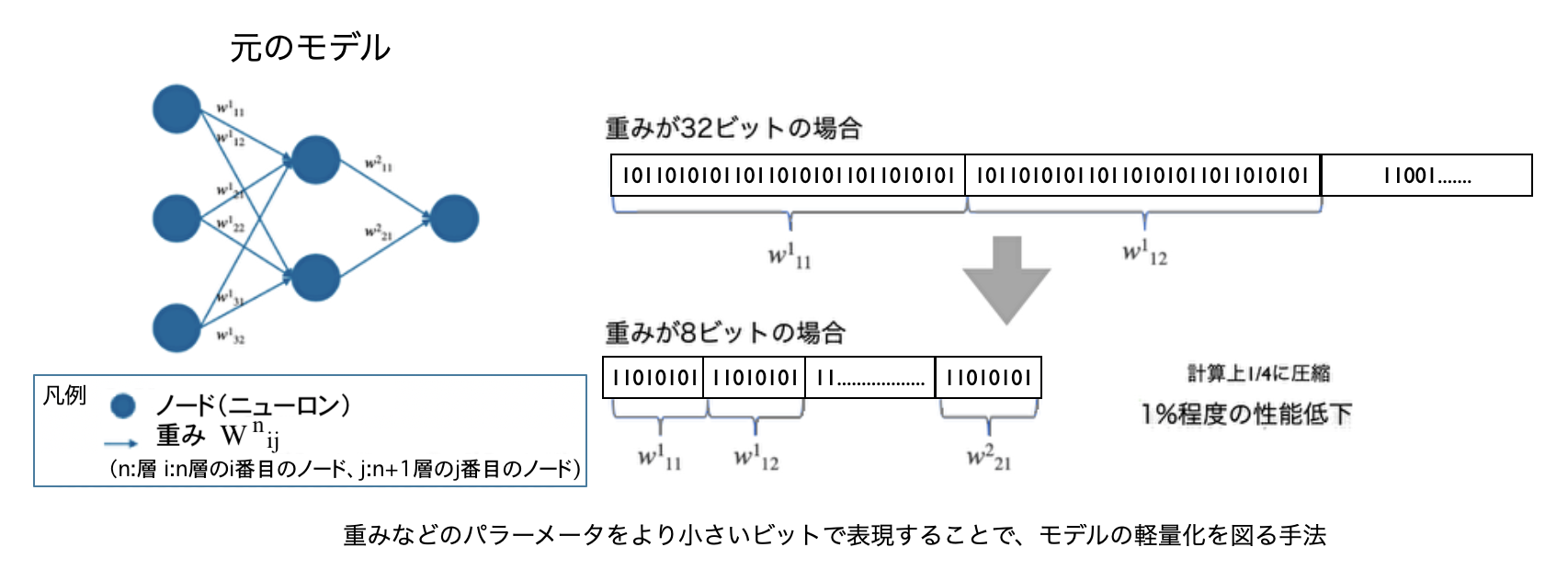
量子化
重みなどの関数パラーメータをより小さいビットで表現し、計算量を小さくすることで軽量化を図る手法です。
計算のまるめともいいます。
TensorFlowやPyTorchなどのディープラーニングのフレームワークでは、
32ビット浮動小数点精度(float型)を使用することがほとんどです。
8ビットの量子化であれば1%程度の性能低下であることが報告されています。
ここが研究開発のキモで、精度を下げずに小さいビットで表現することで小型化を実現します。
当社のアルゴリズムでは、1/10の小型化(10倍の高速化)に成功しています。
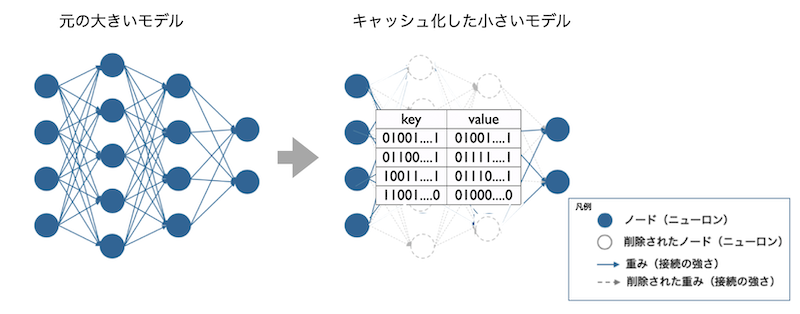
キャッシュAI
モデルの中間層の関数計算すべてをハッシュ値(元データから一定の計算手順により求められた固定長の値。暗号化に用いられる)のテーブルに変換する、当社の発明技術です。(特許技術)
Key Value 型(key の値に対してValue の値が一対一対応する)のハッシュテーブルの暗号化
技術を用いており、元データを暗号化する性質も備えています。
課題は、ハッシュテーブルを巨大化させないように、多様なデータで同じテーブルで利用できることであり、
多様な画像の部分データが関数計算され正しく変換されたKey 値がテーブルのValue 値に当たるかのヒット率
(認識の精度)を実用化レベルにするのが難しいポイントです。
例えば、薬局の処方箋認識であれば実務で使うには90%以上にする必要があります。
難しい課題をクリアし、1/10 以下に小型化できる可能性がある、画期的な技術に取り組んでいます。