AI Model downsizing technology
AI Model downsizing technology
Purpose
Since our founding, we have been researching and developing AI model compression technology. Focusing on server costs, as an issue in the actual operation of AI, we have researched and developed compression of AI to reduce server cost.
Smaller trained models can speed up processing. This reduces the server processing load required to operate trained models and reduces server costs, which accounted for most of the cost of AI product services, so that product services can be provided at economical prices.
Our technologies
There are various methods of AI dropdown, but our company mainly researches and develops two methods Quantization and our own Cache AI method.
Before explaining the dropdown method, let me briefly explain Weighting for deep learning beginners.
Deep learning has Training and Inference (Prediction). load a large amount of data into a neural network, Training means creating a network that optimally adjusts the Weighting of synapses.
In the case of bear image recognition, after
a model is “learned” a bear dataset, it is input an image and it inferences “There is a 90% probability that it is a bear.”
If the given image is not a bear image, the recognition accuracy called be poor.
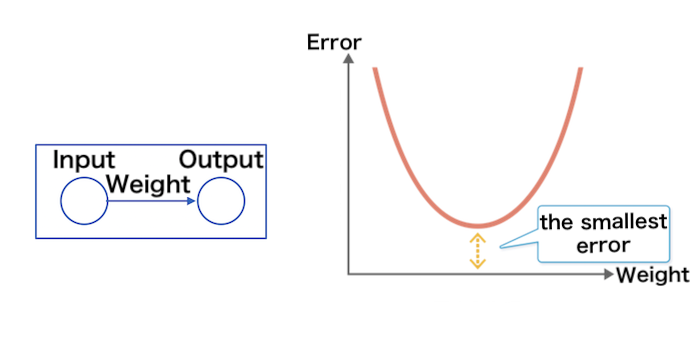
Using the method of Backpropagation, it is adjusted the “error” is the difference between the input “bear” and the output.
This is a method of calculating the synapse Weighting to minimize this error in the opposite direction from the output to the input.
Deep learning continues to adjust the Weighting in the neural network and learns the bear image.
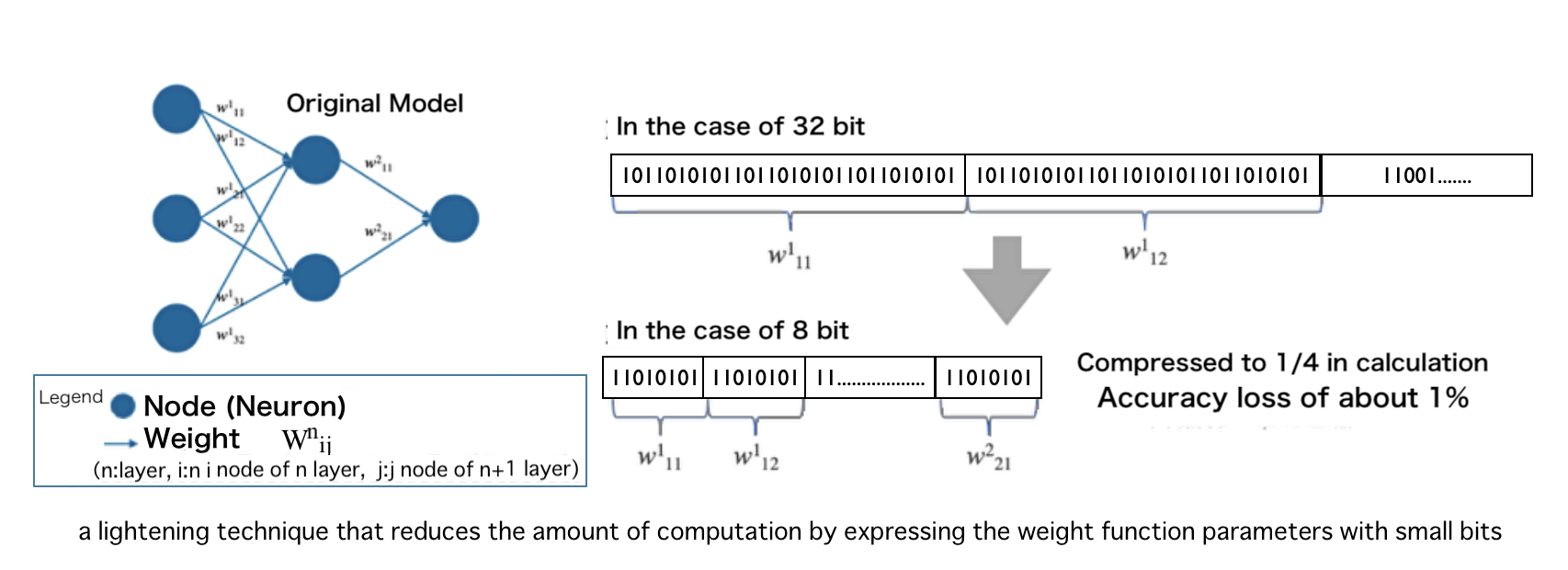
Quantization
This is a lightening technique that reduces the amount of computation by expressing the weight function parameters with small bits.
This is also known as arithmetic rounding.
In deep learning frameworks such as TensorFlow and PyTorch,
32-bit floating point precision (float type) is the most used.
It has been reported that 8-bit quantization results in a performance degradation of about 1%.
This is the key to research and development, and miniaturization is achieved by expressing with small bits without lowering accuracy.
Our algorithm has succeeded in making the trained model 1/10th smaller (10 times faster).
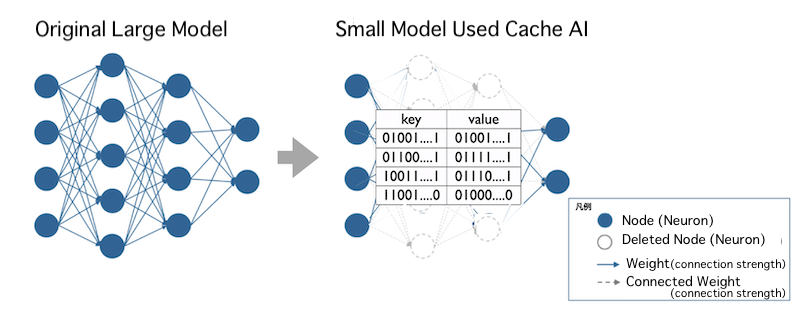
Cache AI
This is our invented technology to convert all function calculations in the middle layer of the model into a table of hash values (fixed-length values obtained from the original data by a calculation procedure. Used for encryption). (Patented technology)
It uses key-value type hash table encryption technology (one-to-one correspondence between key and value pair), and it also has the property of encrypting the original data.
The challenge can be to use various data in the same table without enlarging the hash table.
It is difficult to make the hit rate (recognition accuracy) of whether the key that is correctly converted by function calculation of various image partial data corresponds to the value of the table (recognition accuracy) to a practical level.
For example, in the case of pharmacy prescription recognition, it needs to be 90% or higher for practical use.
Clearing this issue, we are working on a groundbreaking technology that has the potential to reduce the size to 1/10 or less.